
Despite the increasing popularity of Bayesian inference in empirical research, few practical guidelines provide detailed recommendations for how to apply Bayesian procedures and interpret the results. Here we offer specific guidelines for four different stages of Bayesian statistical reasoning in a research setting: planning the analysis, executing the analysis, interpreting the results, and reporting the results. The guidelines for each stage are illustrated with a running example. Although the guidelines are geared towards analyses performed with the open-source statistical software JASP, most guidelines extend to Bayesian inference in general.
Avoid common mistakes on your manuscript.
In recent years, Bayesian inference has become increasingly popular, both in statistical science and in applied fields such as psychology, biology, and econometrics (e.g., Andrews & Baguley, 2013; Vandekerckhove, Rouder, & Kruschke, 2018). For the pragmatic researcher, the adoption of the Bayesian framework brings several advantages over the standard framework of frequentist null-hypothesis significance testing (NHST), including (1) the ability to obtain evidence in favor of the null hypothesis and discriminate between “absence of evidence” and “evidence of absence” (Dienes, 2014; Keysers, Gazzola, & Wagenmakers, 2020); (2) the ability to take into account prior knowledge to construct a more informative test (Gronau, Ly, & Wagenmakers, 2020; Lee & Vanpaemel, 2018); and (3) the ability to monitor the evidence as the data accumulate (Rouder, 2014). However, the relative novelty of conducting Bayesian analyses in applied fields means that there are no detailed reporting standards, and this in turn may frustrate the broader adoption and proper interpretation of the Bayesian framework.
Several recent statistical guidelines include information on Bayesian inference, but these guidelines are either minimalist (Appelbaum et al., 2018; The BaSiS group, 2001), focus only on relatively complex statistical tests (Depaoli & Schoot, 2017), are too specific to a certain field (Spiegelhalter, Myles, Jones, & Abrams, 2000; Sung et al., 2005), or do not cover the full inferential process (Jarosz & Wiley, 2014). The current article aims to provide a general overview of the different stages of the Bayesian reasoning process in a research setting. Specifically, we focus on guidelines for analyses conducted in JASP (JASP Team, 2019; jasp-stats.org), although these guidelines can be generalized to other software packages for Bayesian inference. JASP is an open-source statistical software program with a graphical user interface that features both Bayesian and frequentist versions of common tools such as the t test, the ANOVA, and regression analysis (e.g., Marsman & Wagenmakers, 2017; Wagenmakers et al., 2018).
We discuss four stages of analysis: planning, executing, interpreting, and reporting. These stages and their individual components are summarized in Table 1. In order to provide a concrete illustration of the guidelines for each of the four stages, each section features a data set reported by Frisby and Clatworthy (1975). This data set concerns the time it took two groups of participants to see a figure hidden in a stereogram—one group received advance visual information about the scene (i.e., the VV condition), whereas the other group did not (i.e., the NV condition). Footnote 1 Three additional examples (mixed ANOVA, correlation analysis, and a t test with an informed prior) are provided in an online appendix at https://osf.io/nw49j/. Throughout the paper, we present three boxes that provide additional technical discussion. These boxes, while not strictly necessary, may prove useful to readers interested in greater detail.
Once the quality of the data has been confirmed, the planned analyses can be carried out. JASP offers a graphical user interface for both frequentist and Bayesian analyses. JASP 0.10.2 features the following Bayesian analyses: the binomial test, the Chi-square test, the multinomial test, the t test (one-sample, paired sample, two-sample, Wilcoxon rank-sum, and Wilcoxon signed-rank tests), A/B tests, ANOVA, ANCOVA, repeated measures ANOVA, correlations (Pearson’s ρ and Kendall’s τ), linear regression, and log-linear regression. After loading the data into JASP, the desired analysis can be conducted by dragging and dropping variables into the appropriate boxes; tick marks can be used to select the desired output.
The resulting output (i.e., figures and tables) can be annotated and saved as a .jasp file. Output can then be shared with peers, with or without the real data in the .jasp file; if the real data are added, reviewers can easily reproduce the analyses, conduct alternative analyses, or insert comments.
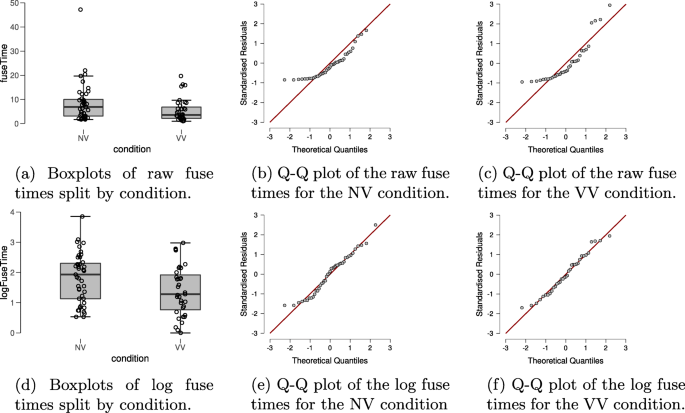
In order to check for violations of the assumptions of the t test, the top row of Fig. 2 shows boxplots and Q-Q plots of the dependent variable fuse time, split by condition. Visual inspection of the boxplots suggests that the variances of the fuse times may not be equal (observed standard deviations of the NV and VV groups are 8.085 and 4.802, respectively), suggesting the equal variance assumption may be unlikely to hold. There also appear to be a number of potential outliers in both groups. Moreover, the Q-Q plots show that the normality assumption of the t test is untenable here. Thus, in line with our analysis plan we will apply the log-transformation to the fuse times. The standard deviations of the log-transformed fuse times in the groups are roughly equal (observed standard deviations are 0.814 and 0.818 in the NV and the VV group, respectively); the Q-Q plots in the bottom row of Fig. 2 also look acceptable for both groups and there are no apparent outliers. However, it seems prudent to assess the robustness of the result by also conducting the Bayesian Mann–Whitney U test (van Doorn, Ly, Marsman, & Wagenmakers, 2020) on the fuse times.
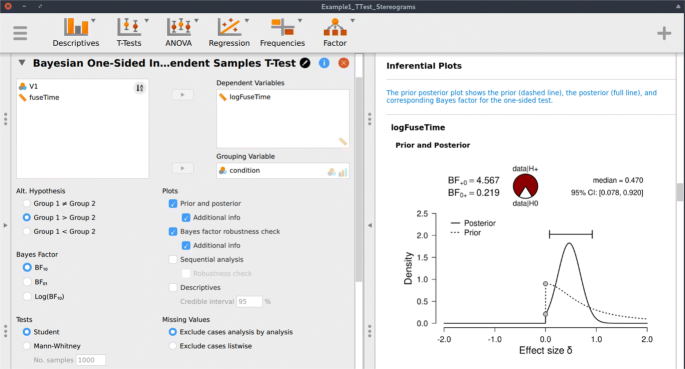
Following the assumption check, we proceed to execute the analyses in JASP. For hypothesis testing, we obtain a Bayes factor using the one-sided Bayesian two-sample t test. Figure 3 shows the JASP user interface for this procedure. For parameter estimation, we obtain a posterior distribution and credible interval, using the two-sided Bayesian two-sample t test. The relevant boxes for the various plots were ticked, and an annotated .jasp file was created with all of the relevant analyses: the one-sided Bayes factor hypothesis tests, the robustness check, the posterior distribution from the two-sided analysis, and the one-sided results of the Bayesian Mann–Whitney U test. The .jasp file can be found at https://osf.io/nw49j/. The next section outlines how these results are to be interpreted.
With the analysis outcome in hand, we are ready to draw conclusions. We first discuss the scenario of hypothesis testing, where the goal typically is to conclude whether an effect is present or absent. Then, we discuss the scenario of parameter estimation, where the goal is to estimate the size of the population effect, assuming it is present. When both hypothesis testing and estimation procedures have been planned and executed, there is no predetermined order for their interpretation. One may adhere to the adage “only estimate something when there is something to be estimated” (Wagenmakers et al., 2018) and first test whether an effect is present, and then estimate its size (assuming the test provided sufficiently strong evidence against the null), or one may first estimate the magnitude of an effect, and then quantify the degree to which this magnitude warrants a shift in plausibility away from or toward the null hypothesis (but see Box 3).
If the goal of the analysis is hypothesis testing, we recommend using the Bayes factor. As described in Box 1, the Bayes factor quantifies the relative predictive performance of two rival hypotheses (Wagenmakers et al., 2016; see Box 1). Importantly, the Bayes factor is a relative metric of the hypotheses’ predictive quality. For instance, if BF10 = 5, this means that the data are 5 times more likely under \(<\mathscr
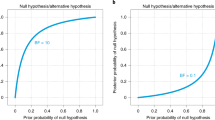
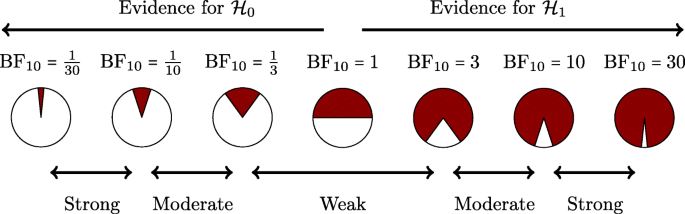
There can be no hard Bayes factor bound (other than zero and infinity) for accepting or rejecting a hypothesis wholesale, but there have been some attempts to classify the strength of evidence that different Bayes factors provide (e.g., Jeffreys, 1939; Kass & Raftery, 1995). One such classification scheme is shown in Figure 4. Several magnitudes of the Bayes factor are visualized as a probability wheel, where the proportion of red to white is determined by the degree of evidence in favor of \(<\mathscr
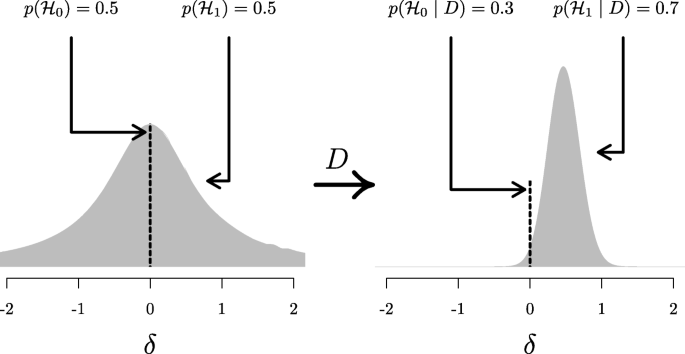
When the goal of the analysis is parameter estimation, the posterior distribution is key (see Box 2). The posterior distribution is often summarized by a location parameter (point estimate) and uncertainty measure (interval estimate). For point estimation, the posterior median (reported by JASP), mean, or mode can be reported, although these do not contain any information about the uncertainty of the estimate. In order to capture the uncertainty of the estimate, an x% credible interval can be reported. The credible interval [L,U] has a x% probability that the true parameter lies in the interval that ranges from L to U (an interpretation that is often wrongly attributed to frequentist confidence intervals, see Morey, Hoekstra, Rouder, Lee, & Wagenmakers, 2016). For example, if we obtain a 95% credible interval of [− 1,0.5] for effect size δ, we can be 95% certain that the true value of δ lies between − 1 and 0.5, assuming that the alternative hypothesis we specify is true. In case one does not want to make this assumption, one can present the unconditional posterior distribution instead. For more discussion on this point, see Box 3.
Bayesian veterans sometimes argue that Bayesian concepts are intuitive and easier to grasp than frequentist concepts. However, in our experience there exist persistent misinterpretations of Bayesian results. Here we list five:
In order to avoid these and other pitfalls, we recommend that researchers who are doubtful about the correct interpretation of their Bayesian results solicit expert advice (for instance through the JASP forum at http://forum.cogsci.nl).
For hypothesis testing, the results of the one-sided t test are presented in Fig. 6a. The resulting BF+ 0 is 4.567, indicating moderate evidence in favor of \(<\mathscr
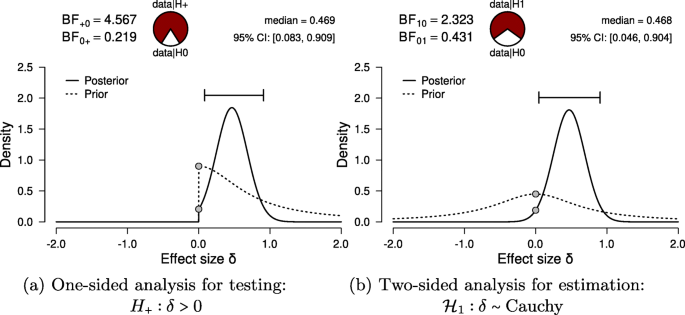
For parameter estimation, the results of the two-sided t test are presented in Fig. 6a. The 95% central credible interval for δ is relatively wide, ranging from 0.046 to 0.904: this means that, under the assumption that the effect exists and given the model we specified, we can be 95% certain that the true value of δ lies between 0.046 to 0.904. In conclusion, there is moderate evidence for the presence of an effect, and large uncertainty about its size.
For increased transparency, and to allow a skeptical assessment of the statistical claims, we recommend to present an elaborate analysis report including relevant tables, figures, assumption checks, and background information. The extent to which this needs to be done in the manuscript itself depends on context. Ideally, an annotated .jasp file is created that presents the full results and analysis settings. The resulting file can then be uploaded to the Open Science Framework (OSF; https://osf.io), where it can be viewed by collaborators and peers, even without having JASP installed. Note that the .jasp file retains the settings that were used to create the reported output. Analyses not conducted in JASP should mimic such transparency, for instance through uploading an R-script. In this section, we list several desiderata for reporting, both for hypothesis testing and parameter estimation. What to include in the report depends on the goal of the analysis, regardless of whether the result is conclusive or not.
In all cases, we recommend to provide a complete description of the prior specification (i.e., the type of distribution and its parameter values) and, especially for informed priors, to provide a justification for the choices that were made. When reporting a specific analysis, we advise to refer to the relevant background literature for details. In JASP, the relevant references for specific tests can be copied from the drop-down menus in the results panel.
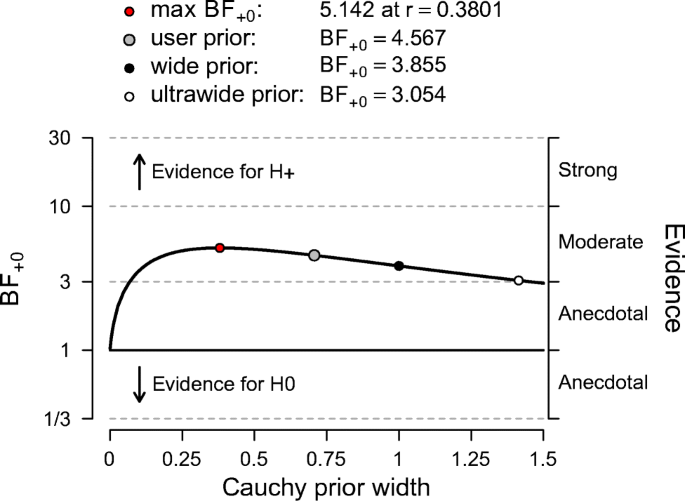
When the goal of the analysis is hypothesis testing, it is key to outline which hypotheses are compared by clearly stating each hypothesis and including the corresponding subscript in the Bayes factor notation. Furthermore, we recommend to include, if available, the Bayes factor robustness check discussed in the section on planning (see Fig. 7 for an example). This check provides an assessment of the robustness of the Bayes factor under different prior specifications: if the qualitative conclusions do not change across a range of different plausible prior distributions, this indicates that the analysis is relatively robust. If this plot is unavailable, the robustness of the Bayes factor can be checked manually by specifying several different prior distributions (see the mixed ANOVA analysis in the online appendix at https://osf.io/wae57/ for an example). When data come in sequentially, it may also be of interest to examine the sequential Bayes factor plot, which shows the evidential flow as a function of increasing sample size.
When the goal of the analysis is parameter estimation, it is important to present a plot of the posterior distribution, or report a summary, for instance through the median and a 95% credible interval. Ideally, the results of the analysis are reported both graphically and numerically. This means that, when possible, a plot is presented that includes the posterior distribution, prior distribution, Bayes factor, 95% credible interval, and posterior median. Footnote 8
Numeric results can be presented either in a table or in the main text. If relevant, we recommend to report the results from both estimation and hypothesis test. For some analyses, the results are based on a numerical algorithm, such as Markov chain Monte Carlo (MCMC), which yields an error percentage. If applicable and available, the error percentage ought to be reported too, to indicate the numeric robustness of the result. Lower values of the error percentage indicate greater numerical stability of the result. Footnote 9 In order to increase numerical stability, JASP includes an option to increase the number of samples for MCMC sampling when applicable.
This is an example report of the stereograms t test example:
Here we summarize the results of the Bayesian analysis for the stereogram data. For this analysis we used the Bayesian t test framework proposed by (see also; Jeffreys, 1961; Rouder et al., 2009). We analyzed the data with JASP (JASP Team, 2019). An annotated .jasp file, including distribution plots, data, and input options, is available at https://osf.io/25ekj/. Due to model misspecification (i.e., non-normality, presence of outliers, and unequal variances), we applied a log-transformation to the fuse times. This remedied the misspecification. To assess the robustness of the results, we also applied a Mann–Whitney U test.
First, we discuss the results for hypothesis testing. The null hypothesis postulates that there is no difference in log fuse time between the groups and therefore \(<\mathscr
Second, we discuss the results for parameter estimation. Of interest is the posterior distribution of the standardized effect size δ (i.e., the population version of Cohen’s d, the standardized difference in mean fuse times). For parameter estimation, δ was assigned a Cauchy prior distribution with \(r =/>\) . Figure 6b shows that the median of the resulting posterior distribution for δ equals 0.47 with a central 95% credible interval for δ that ranges from 0.046 to 0.904. If the effect is assumed to exist, there remains substantial uncertainty about its size, with values close to 0 having the same posterior density as values close to 1.
The Bayesian toolkit for the empirical social scientist still has some limitations to overcome. First, for some frequentist analyses, the Bayesian counterpart has not yet been developed or implemented in JASP. Secondly, some analyses in JASP currently provide only a Bayes factor, and not a visual representation of the posterior distributions, for instance due to the multidimensional parameter space of the model. Thirdly, some analyses in JASP are only available with a relatively limited set of prior distributions. However, these are not principled limitations and the software is actively being developed to overcome these limitations. When dealing with more complex models that go beyond the staple analyses such as t tests, there exist a number of software packages that allow custom coding, such as JAGS (Plummer, 2003) or Stan (Carpenter et al., 2017). Another option for Bayesian inference is to code the analyses in a programming language such as R (R Core Team, 2018) or Python (van Rossum, 1995). This requires a certain degree of programming ability, but grants the user more flexibility. Popular packages for conducting Bayesian analyses in R are the BayesFactor package (Morey & Rouder, 2015) and the brms package (Bürkner, 2017), among others (see https://cran.r-project.org/web/views/Bayesian.html for a more exhaustive list). For Python, a popular package for Bayesian analyses is PyMC3 (Salvatier, Wiecki, & Fonnesbeck, 2016). The practical guidelines provided in this paper can largely be generalized to the application of these software programs.
We have attempted to provide concise recommendations for planning, executing, interpreting, and reporting Bayesian analyses. These recommendations are summarized in Table 1. Our guidelines focused on the standard analyses that are currently featured in JASP. When going beyond these analyses, some of the discussed guidelines will be easier to implement than others. However, the general process of transparent, comprehensive, and careful statistical reporting extends to all Bayesian procedures and indeed to statistical analyses across the board.
The variables are participant number, the time (in seconds) each participant needed to see the hidden figure (i.e., fuse time), experimental condition (VV = with visual information, NV = without visual information), and the log-transformed fuse time.
A one-sided alternative hypothesis makes a more risky prediction than a two-sided hypothesis. Consequently, if the data are in line with the one-sided prediction, the one-sided alternative hypothesis is rewarded with a greater gain in plausibility compared to the two-sided alternative hypothesis; if the data oppose the one-sided prediction, the one-sided alternative hypothesis is penalized with a greater loss in plausibility compared to the two-sided alternative hypothesis.
The fat-tailed Cauchy distribution is a popular default choice because it fulfills particular desiderata, see (Jeffreys, 1961;Liang, German, Clyde, & Berger, 2008; Ly et al., 2016; Rouder, Speckman, Sun, Morey, & Iverson, 2009) for details.
Specifically, the proportion of red is the posterior probability of \(<\mathscr
This is known as Jeffreys’s platitude: “The most beneficial result that I can hope for as a consequence of this work is that more attention will be paid to the precise statement of the alternatives involved in the questions asked. It is sometimes considered a paradox that the answer depends not only on the observations but on the question; it should be a platitude” (Jeffreys, 1939, p.vi).
The Bayesian Mann–Whitney U test results and the results for the raw fuse times are in the .jasp file at https://osf.io/nw49j/.
The posterior median is popular because it is robust to skewed distributions and invariant under smooth transformations of parameters, although other measures of central tendency, such as the mode or the mean, are also in common use.
We generally recommend error percentages below 20% as acceptable. A 20% change in the Bayes factor will result in one making the same qualitative conclusions. However, this threshold naturally increases with the magnitude of the Bayes factor. For instance, a Bayes factor of 10 with a 50% error percentage could be expected to fluctuate between 5 and 15 upon recomputation. This could be considered a large change. However, with a Bayes factor of 1000 a 50% reduction would still leave us with overwhelming evidence.
We thank Dr. Simons, two anonymous reviewers, and the editor for comments on an earlier draft. Correspondence concerning this article may be addressed to Johnny van Doorn, University of Amsterdam, Department of Psychological Methods, Valckeniersstraat 59, 1018 XA Amsterdam, the Netherlands. E-mail may be sent to johnnydoorn@gmail.com. This work was supported in part by a Vici grant from the Netherlands Organization of Scientific Research (NWO) awarded to EJW (016.Vici.170.083) and an advanced ERC grant awarded to EJW (743086 UNIFY). DM is supported by a Veni Grant (451-15-010) from the NWO. MM is supported by a Veni Grant (451-17-017) from the NWO. AE is supported by a National Science Foundation Graduate Research Fellowship (DGE1321846). Centrum Wiskunde & Informatica (CWI) is the national research institute for mathematics and computer science in the Netherlands.